
構造化データとは
構造化データ(Structured Data)とは、次のような表形式で初めから与えられているデータのことをいいます。[1]本例は、Rにプリセットされているirisデータセットより。
Sepal.Length、Sepal.Width、Petal.Length、Petal.Width、Speciesは変数の名前、下に続く数字や文字は各変数の値です。
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5 | 3.6 | 1.4 | 0.2 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
| 7 | 3.2 | 4.7 | 1.4 | versicolor |
| 6.4 | 3.2 | 4.5 | 1.5 | versicolor |
| 6.9 | 3.1 | 4.9 | 1.5 | versicolor |
| 5.5 | 2.3 | 4 | 1.3 | versicolor |
| 6.5 | 2.8 | 4.6 | 1.5 | versicolor |
| 5.7 | 2.8 | 4.5 | 1.3 | versicolor |
| 6.3 | 3.3 | 6 | 2.5 | virginica |
| 5.8 | 2.7 | 5.1 | 1.9 | virginica |
| 7.1 | 3 | 5.9 | 2.1 | virginica |
| 6.3 | 2.9 | 5.6 | 1.8 | virginica |
| 6.5 | 3 | 5.8 | 2.2 | virginica |
| 7.6 | 3 | 6.6 | 2.1 | virginica |
コンピューター上で数値計算を行うためには、データをベクトルや行列として扱う必要があります。このような形式でデータが与えられていれば、データフレームなどのデータ構造を使用することにより、そのまま入力とすることが可能です。
構造化データの代表例が、RDB(Relational Database)です。RDBはSQLを用いて問い合わせ(クエリ)を行いますが、SQLは”Structured Query Language”の略で、そのまま「構造化問い合わせ言語」です。
RDBに容易に登録可能な形式で作成されたCSVファイル(拡張子「.csv」)およびCSV型式のデータも、広義の構造化データといえます。CSV(Comma-Separated Values)は、カンマ「,」で区切ることを特徴としたデータ記述言語です。
「(Excelなど)表計算ソフトと構造化データの違い」については、次の記事をご参照ください。

非構造化データとは
非構造化データ(Unstructured Data)とは、文字通り「構造化されていないデータ」です。非構造化データの代表的なものとして、画像データ、音声データ、自然言語データ(テキストデータ)があります。[2]本サイトでは時系列データは、構造化データと非構造化データのいずれにも含まれないものとして考えます。
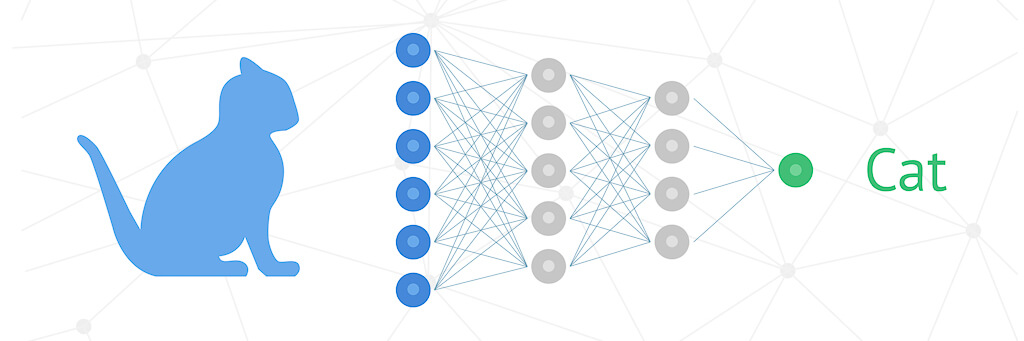
機械学習の説明としてよく、「ネコの画像」を(正しく)「ネコ(Cat)」と分類する、というものがあります。「ネコの画像」は画像データであり、非構造化データの一種です。
音声データは、そのまま人間の発する音声(声の音)のデータです。実用化されているものとして、テキストアプリの音声入力機能などがあります。[3] … Continue reading
自然言語とは、我々人間がコミュニケーションをとるために自然に使っている言語です。この文章そのものが、自然言語です。[4]自然言語でない言語の例としては、プログラミング言語があります。
深層学習(ディープラーニング)を含むニューラルネットワークは特に、非構造化データに対する有用性が高いことで知られています。
非構造化データを対象とした機械学習タスクの多くは、人間の認知能力(cognitive ability)を代替することを目的としています。「ネコの画像」を見て「ネコ」と人間が認知する代わりに、機械(人口知能)にそれをさせようということです。
こうしたタスクはコモディティ化が進みやすく、既に様々な機能がAPIとして提供されています。


