
Irisデータセットとは
Irisデータセットは、データサイエンスの世界でもっとも有名なデータセットのひとつです。
統計学に多大な功績を残したロナルド・エイルマー・フィッシャー(Ronald Aylmer Fisher)が論文で使用したデータセットであることから、フィッシャーのIrisデータセット(Fisher’s Iris Dataset)と呼ばれることもあります。
Irisは日本語で「アヤメ」と呼ばれる花です。生物分類として科・属・種がありますが、日本で単に「アヤメ」といった場合は、通常アヤメ科アヤメ属アヤメを指します。[1]アヤメ科アヤメ属の中で、他に日本で有名な花としては、カキツバタやハナショウブなどがあります。
Irisデータセットでは、アヤメ科アヤメ属の中でsetosa、versicolor、virginicaという3種の花に着目しています。
setosa、versicolor、virginicaは、素人にはほとんど同じような花に見えます。しかしがく片(sepal)の長さ、幅、および花弁(petal)の長さ、幅を測定、分析することによって、それらを区別するための特徴が見えてきます。setosa、versicolor、virginicaそれぞれ、50個体について測定しています。
下記がそのデータセットです。一部を抜き出していますが、全部で150行5列あります。
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5 | 3.6 | 1.4 | 0.2 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
| 7 | 3.2 | 4.7 | 1.4 | versicolor |
| 6.4 | 3.2 | 4.5 | 1.5 | versicolor |
| 6.9 | 3.1 | 4.9 | 1.5 | versicolor |
| 5.5 | 2.3 | 4 | 1.3 | versicolor |
| 6.5 | 2.8 | 4.6 | 1.5 | versicolor |
| 5.7 | 2.8 | 4.5 | 1.3 | versicolor |
| 6.3 | 3.3 | 6 | 2.5 | virginica |
| 5.8 | 2.7 | 5.1 | 1.9 | virginica |
| 7.1 | 3 | 5.9 | 2.1 | virginica |
| 6.3 | 2.9 | 5.6 | 1.8 | virginica |
| 6.5 | 3 | 5.8 | 2.2 | virginica |
| 7.6 | 3 | 6.6 | 2.1 | virginica |
各列の説明
繰り返しになりますが、各列の説明は下記です。
| 列名 | 説明 |
|---|---|
| Sepal.Length | がく片の長さ [cm] |
| Sepal.Width | がく片の幅 [cm] |
| Petal.Length | 花弁の長さ [cm] |
| Petal.Width | 花弁の幅 [cm] |
| Species | 花の種類 (setosa、versicolor、virginicaの3種) |
Irisデータセットの読み込み
Irisデータセットを読み込み、dfという名前の変数に代入します。
Rでは標準的に、irisという名前のデータフレームが用意(プリセット)されています。
df <- iris
Pythonではいくつか方法がありますが、ここではライブラリSeabornから読み込む方法をご紹介します[2]ライブラリscikit-learnから読み込む方法もあります。。
import seaborn as sns
df = sns.load_dataset('iris')
SeabornのIrisデータセットは、Pandasのデータフレーム(Pandas.DataFrame)として用意されています。Rのデータセットと比べると、列名の大文字が小文字になったり、ピリオド(.)がアンダーバー(_)になったりという若干の差異はあります。
Irisデータセットのデータ型
各列のデータ型(data type)を調べます。
Rでは、str関数[3]str関数のstrはstring(文字列)ではなく、structure(構造)の略です。を使用します。
str(df)
'data.frame': 150 obs. of 5 variables: $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ... $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ... $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ... $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ... $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
Sepal.Length~Sepal.Lengthはnumeric型(数値型)、Speciesはfactor型(因子型)[4]Rでは、質的変数をcharacter型として扱う方法(流儀)もあります。です。
Pythonでは、Pandas.DataFrameのdtypes属性を確認します。
df.dtypes
sepal_length float64 sepal_width float64 petal_length float64 petal_width float64 species object dtype: object
sepal_length~petal_widthはfloat64型(倍精度浮動小数点型)、speciesはobject型(オブジェクト型)[5]Pythonでは、質的変数をcategory型として扱う方法(流儀)もあります。です。
Irisデータセットの要約統計量
各列の要約統計量を確認します。
Rでは、summary関数を使用します。
summary(df)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100 setosa :50 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300 versicolor:50 Median :5.800 Median :3.000 Median :4.350 Median :1.300 virginica :50 Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800 Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
Sepal.Length~Petal.Widthは中央値(Median)を含む四分位数(1st Qu.、Median、3rd Qu.)と平均値(Mean)、最小値(Min.)、最大値(Max.)が、Speciesは各階級(クラス)の度数が表示されています。
setosa、versicolor、virginicaはそれぞれ、50行ずつあることが確認できます。
Pythonでは、pandas.DataFrameのdescribeメソッドを使用します。
df.describe()
sepal_length sepal_width petal_length petal_width count 150.000000 150.000000 150.000000 150.000000 mean 5.843333 3.057333 3.758000 1.199333 std 0.828066 0.435866 1.765298 0.762238 min 4.300000 2.000000 1.000000 0.100000 25% 5.100000 2.800000 1.600000 0.300000 50% 5.800000 3.000000 4.350000 1.300000 75% 6.400000 3.300000 5.100000 1.800000 max 7.900000 4.400000 6.900000 2.500000
sepal_length~petal_widthは中央値(50%)を含む四分位数(25%、50%、75%)と平均値(mean)、標準偏差(std)、最小値(min)、最大値(max)および欠損値を除く個数(count)が表示されています。
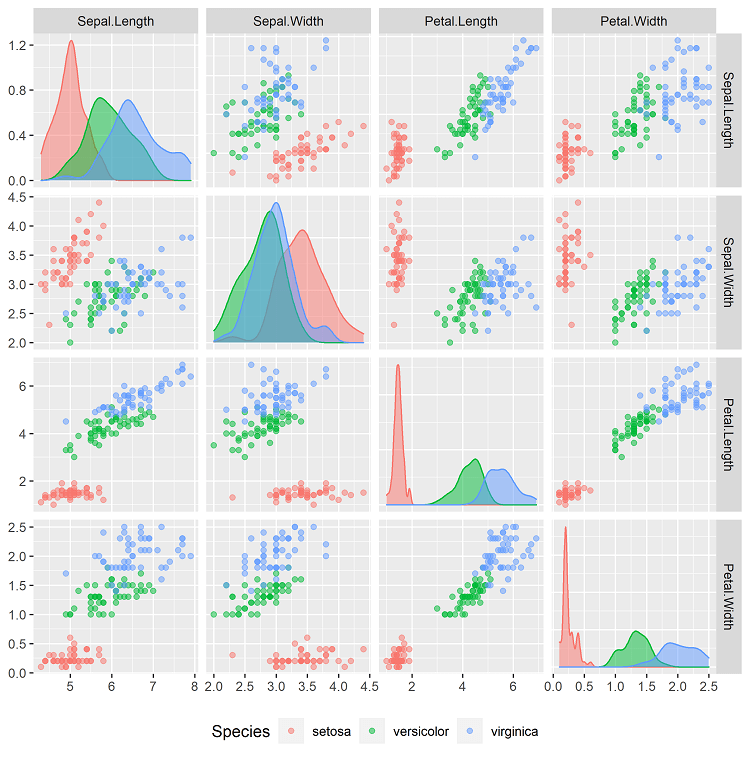
Irisデータセットの散布図行列
Irisデータセットの散布図行列(pairplot)[6]列同士をペアにして、すべてのペアで散布図を並べたもの。を描きます。
Rではいくつか方法がありますが、ここではライブラリGGallyのggpairs関数を使用します。[7]体裁のためにコードが長くなっていますが、ggpairs(df)だけでデフォルトの散布図行列を、ggpairs(df, mapping = aes(colour = … Continue reading
library(GGally)
# 散布図行列
ggpairs(df,
columns = 1:4,
mapping = aes(fill = Species, colour = Species),
upper = list(continuous = wrap('points', alpha = 0.5)),
diag = list(continuous = wrap('densityDiag', alpha = 0.5)),
lower = list(continuous = wrap('points', alpha = 0.5)),
legend = 2) +
theme(legend.position = 'bottom')
Pythonではいくつか方法がありますが、ここではライブラリSeabornのpairplotメソッドを使用します。[8]体裁のためにコードが長くなっていますが、sns.pairplot(df)だけでデフォルトの散布図行列を、sns.pairplot(df, hue = … Continue reading
import seaborn as sns
# 散布図行列
g = sns.pairplot(df, hue = 'species')
g._legend.remove()
g.fig.legend(
handles = g._legend_data.values(),
labels = g._legend_data.keys(),
loc = 'lower center', ncol = 3,
title = 'species')
g.fig.subplots_adjust(bottom = 0.12)
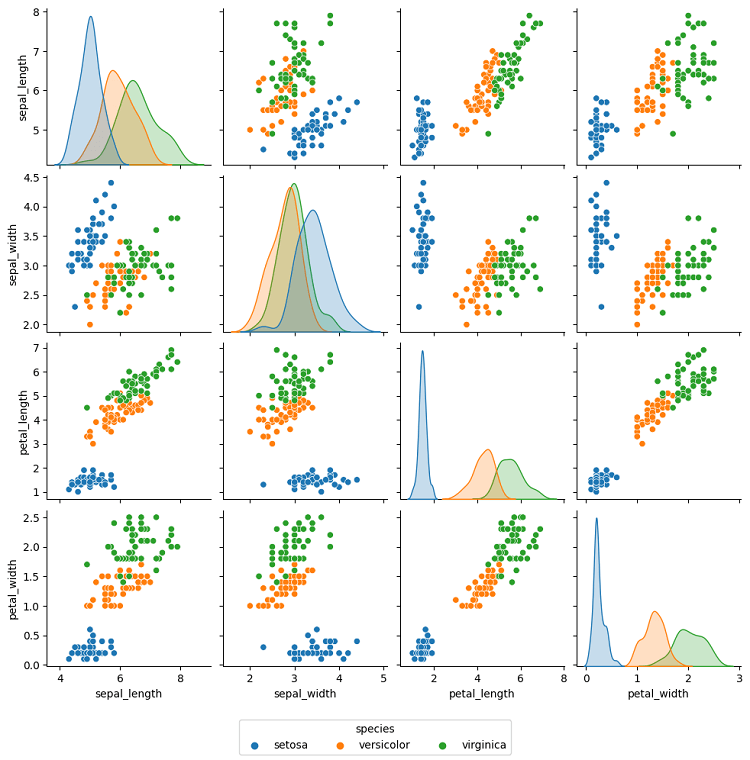
RとPythonどちらの図を見ても同じですが、setosaはPetal.Length(petal_length)またはPetal.Width(petal_width)の1変数だけを使って、容易に判別可能なことがわかります。
versicolorとvirginicaは点が重なっている部分があり、精度100%の分類は難しそうです。しかしPetal.LengthやPetal.Widthの値が大きくなるほど、virginicaの割合が大きくなるという、およその傾向は読み取ることができます。
脚注
| 1 | アヤメ科アヤメ属の中で、他に日本で有名な花としては、カキツバタやハナショウブなどがあります。 |
|---|---|
| 2 | ライブラリscikit-learnから読み込む方法もあります。 |
| 3 | str関数のstrはstring(文字列)ではなく、structure(構造)の略です。 |
| 4 | Rでは、質的変数をcharacter型として扱う方法(流儀)もあります。 |
| 5 | Pythonでは、質的変数をcategory型として扱う方法(流儀)もあります。 |
| 6 | 列同士をペアにして、すべてのペアで散布図を並べたもの。 |
| 7 | 体裁のためにコードが長くなっていますが、ggpairs(df)だけでデフォルトの散布図行列を、ggpairs(df, mapping = aes(colour = Species))だけで色分けした散布図行列を描くことが可能です。 |
| 8 | 体裁のためにコードが長くなっていますが、sns.pairplot(df)だけでデフォルトの散布図行列を、sns.pairplot(df, hue = 'species')だけで色分けした散布図行列を描くことが可能です。 |

