
データサイエンスとは
データサイエンス(Data Science)とは何でしょうか?
『デジタル大辞泉』(小学館)には、次のようにあります。
データの分析についての学問分野。統計学、数学、計算機科学などと関連し、主に大量のデータから、何らかの意味のある情報、法則、関連性などを導き出すこと、またはその処理の手法に関する研究を行う。これらの研究者および技術者はデータサイエンティストとよばれる。
データサイエンスは、「データの分析についての学問分野」です。「統計学、数学、計算機科学などと関連」します。学問分野としてのデータサイエンスで補足します。
「主に大量のデータから」とありますが、「大量のデータ」(ビッグデータ)だけを扱うわけではありません。「大量のデータ」を得られない、といった状況はしばしば発生します。少量のデータから、いかにデータの価値を最大化するかもデータサイエンスの主要な課題のひとつです。
また「何らかの意味のある情報、法則、関連性などを導き出すこと」もよく見られる説明ではありますが、データが既に取得されている、与えられている前提で、そこに何らかの価値を発見するといった印象を与えるかもしれません。“Garbage In, Garbage Out”(ゴミを入力すれば、ゴミが出力される)という言葉がありますが、ゴミのようなデータをいくら高度なアルゴリズムを駆使してこねくり回しても、ゴミにしかなりません。目的意識を持ってデータを取得することが重要です。どのようなデータを取得すべきかといった積極的な提案も、データサイエンティストの役割として求められています。またそうしたデータをいかに効率的に取得するかも、やはりデータサイエンスにおける課題です。
最後に、「これらの研究者および技術者はデータサイエンティストとよばれる」とあります。データサイエンスとデータサイエンティストの関係についてはすこしこみいったものがありますので、次の記事で改めてご説明します。
学問分野としてのデータサイエンス
2017年、滋賀大学に日本初のデータサイエンス学部が誕生します。その後、横浜市立大学や武蔵野大学などが続き、日本で本格的にデータサイエンスを教える大学が増えています。
じつは「データサイエンス」という言葉が生まれる前から、様々な学問分野でそれに関連した研究が行われてきました。データサイエンスは、統計学、数学、計算機科学、人工知能、制御工学、計量経済学、計量生物学、行動計量学、医療統計学、品質管理、信頼性工学、オペレーションズ・リサーチといった伝統的な学問分野を体系化し、進化させる試みであるともいえるかもしれません[1]データサイエンスが単純に、これら学問分野の上位概念というわけではありません。。
独立したひとつの学部や大学院(研究科)として成立することからもわかるように、データサイエンスが対象とする範囲は膨大です。参考に、滋賀大学データサイエンス学部のカリキュラムツリー(令和3年度以降)を示します。
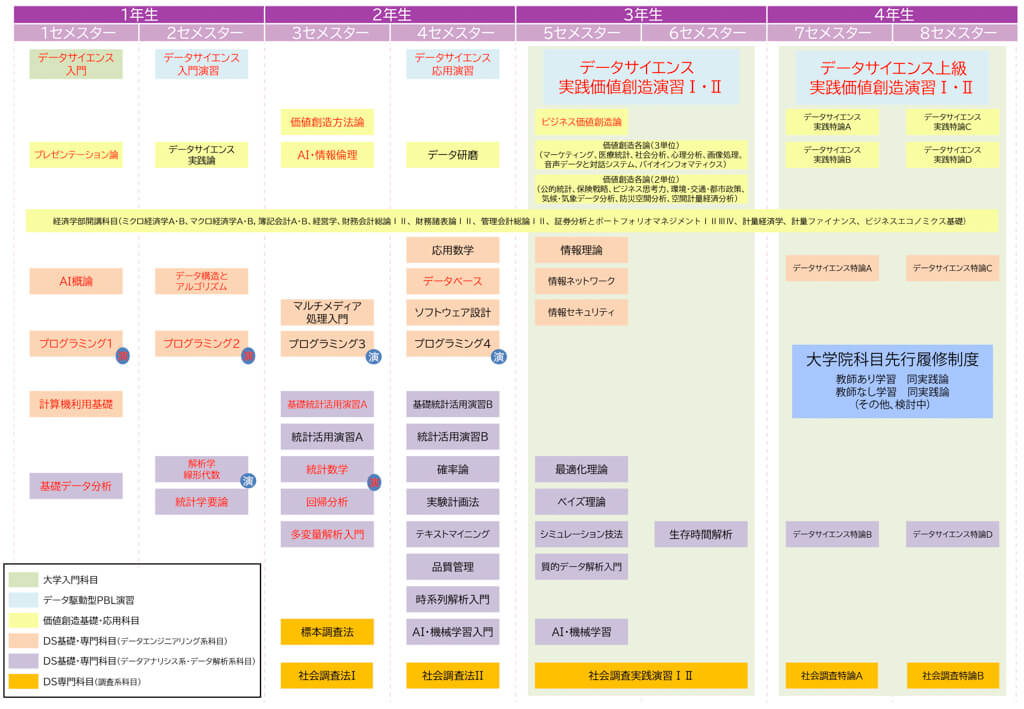
出展:カリキュラム – 滋賀大学 データサイエンス学部 / 研究科
例えば、「実験計画法」は品質管理と関連の深い科目です。「時系列解析入門」は計量経済学および制御工学と、「最適化理論」「シミュレーション技法」はオペレーションズ・リサーチと、「生存時間解析」は医療統計学および信頼性工学と関連の深い科目です。
AI・機械学習についてはやはり比重が大きく、またベイズ理論(ベイズ統計学)の重要性も今後ますます高まっていくものと予想されます。
図の色分けは、データサイエンティストに求められるスキルセットに基づいています。
一般教養としてのデータサイエンス
日本は諸外国と比較して、データサイエンスの活用および教育が遅れているといわれています。こうした問題意識から、文部科学省は「文系理系を問わず、全学的な数理・データサイエンス教育を実施」することを計画しています。
データサイエンスが一般教養になる時代が間もなく訪れようとしています。
しかし本来4年間以上をかけて学ぶものを、数日や数週間で学べるはずはなく、「学問分野としてのデータサイエンス」と「一般教養としてのデータサイエンス」は必然的に異なったものになります。
「一般教養としてのデータサイエンス」というプログラムをどのように組み立てるかは、じっさいかなり難しい問題です。大学4年間のカリキュラムを考えるより、もしかすると難しいかもしれません。あまり手広くしても個々の理解が深まらないため、ある程度ポイントを絞る必要があります。またR, Pythonといったプログラミング言語を使用したくても、どうしても環境構築やコードの説明に時間がとられるため、あまりそれらの比重が大きくなるとプログラミング≒データサイエンスという、誤ったメッセージを与えるおそれが出てくるという問題もあります。予算が許すのであれば、有償ソフトウェアを利用するのも選択肢のひとつです。

データサイエンスのベン図
ドリュー・コンウェイ(Drew Conway)というアメリカのデータサイエンティストが考案した、データサイエンスのベン図(The Data Science Venn Diagram)というものがあります。
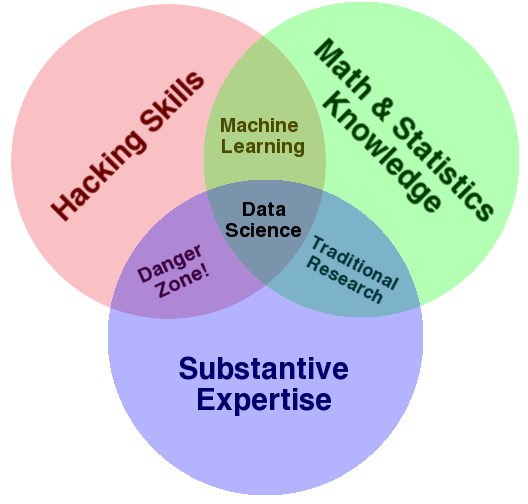
出展:THE DATA SCIENCE VENN DIAGRAM
“Hacking Skills”について、同サイトではドリュー・コンウェイの言葉として、次のように説明されています。日本語はGoogle翻訳です。
Being able to manipulate text files at the command-line, understanding vectorized operations, thinking algorithmically; these are the hacking skills that make for a successful data hacker.
コマンドラインでテキストファイルを操作できること、ベクトル化された操作を理解していること、アルゴリズム的に考えていること。これらは、データハッカーを成功させるためのハッキングスキルです。
“Math & Statistics Knowledge”については、次のような説明があります。
PhD in statistics in required to be a competent data scientist, but it does require knowing what an ordinary least squares regression is and how to interpret it.
統計学の博士号が有能なデータサイエンティストである必要があるということではありませんが、通常の最小二乗回帰とは何か、そしてそれをどのように解釈するかを知る必要があります。
“Machine Learning”(機械学習)と”Substantive Expertise”をあわせて、次のように説明されています。
To me, data plus math and statistics only gets you machine learning, which is great if that is what you are interested in, but not if you are doing data science. Science is about discovery and building knowledge, which requires some motivating questions about the world and hypotheses that can be brought to data and tested with statistical methods.
私にとって、データと数学と統計は機械学習しか得られません。これは、それが興味のあるものである場合は素晴らしいことですが、データサイエンスを行っている場合はそうではありません。科学とは、知識の発見と構築に関するものであり、データに持ち込んで統計的手法でテストできる、世界に関する動機付けの質問と仮説が必要です。
データサイエンスはあくまで科学であり、科学には仮説が必要であるというのがドリュー・コンウェイの考え方です。また機械学習は仮説を必要としないものとして、位置づけられていることがわかります。そもそも機械学習とはなにかということについて、決まった答えがあるわけではありません。これについては改めて、別の記事(準備中)でとりあげたいと思います。
続いて、”Traditional Research”については次のような説明があります。
On the flip-side, substantive expertise plus math and statistics knowledge is where most traditional researcher falls. Doctoral level researchers spend most of their time acquiring expertise in these areas, but very little time learning about technology.
反対に、実質的な専門知識に加えて数学と統計の知識は、ほとんどの伝統的な研究者が当てはまるところです。博士レベルの研究者は、ほとんどの時間をこれらの分野の専門知識の習得に費やしていますが、テクノロジーについて学ぶ時間はほとんどありません。
最後に、もっとも気になるところかもしれませんが”Danger Zone!”については、次のように説明されています。
This is where I place people who, “know enough to be dangerous,” and is the most problematic area of the diagram. In this area people who are perfectly capable of extracting and structuring data, likely related to a field they know quite a bit about, and probably even know enough R to run a linear regression and report the coefficients; but they lack any understanding of what those coefficients mean. It is from this part of the diagram that the phrase “lies, damned lies, and statistics” emanates, because either through ignorance or malice this overlap of skills gives people the ability to create what appears to be a legitimate analysis without any understanding of how they got there or what they have created.
これは、「危険を十分に知っている」人々を配置する場所であり、図の中で最も問題のある領域です。この分野では、データを完全に抽出して構造化する能力があり、おそらくかなり知っている分野に関連しており、線形回帰を実行して係数を報告するのに十分なRを知っている可能性があります。しかし、それらの係数が何を意味するのかについての理解が不足しています。図のこの部分から、「嘘、大嘘、統計」というフレーズが出てきます。無知または悪意によって、このスキルの重複により、人々は、どのように理解していなくても、正当な分析のように見えるものを作成できるからです。
回帰係数の意味を理解しないまま、ただRのコードを走らせただけで、その結果を論文やレポートに載せてしまうのは危険だ、というようなことをいっているのでしょう。それは「統計で嘘をつく」ことになりかねないと。
ドリュー・コンウェイは字義どおり「サイエンス(科学)」という視点で、データサイエンスを論じました。しかし現代ではむしろ「ビジネス」としての視点から、データサイエンスおよびデータサイエンティストが語られることが多い、ということをつけ加えておきます。これについては改めて、次の記事でご説明します。
脚注
| 1 | データサイエンスが単純に、これら学問分野の上位概念というわけではありません。 |
|---|
