
CRISP-DM
データサイエンスのプロセス(ワークフロー)としてとりわけ有名なものに、CRISP-DMがあります。
CRISP-DMは”CRoss-Industry Standard Process for Data Mining”の略で、直訳すると「データマイニングのための業界横断型標準プロセス」です。
CRISP-DMについて詳しくは、下の記事をご参照ください。

CRISP-DM
CRISP-DMとはCRISP-DMは"CRoss-Industry Standard Process for Data Mining"の略で、直訳すると「データマイニングのための業界横断型標準プロセス」です。データマイニングはデータサイエ...
minnanods.com
2021.04.22
Schutt & O’Neil
もうひとつ、データサイエンスのプロセスをご紹介します。
Rachel SchuttとCathy O’Neilの共著『Doing Data Science』の中に掲載されています。
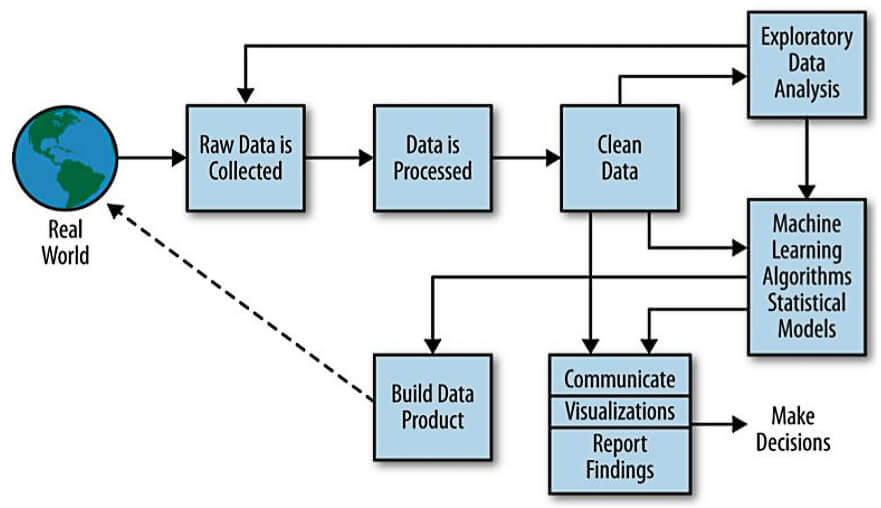
出展:Rachel Schutt, Cathy O’Neil『Doing Data Science』
本プロセスは、以下のステップから構成されています。
- Raw Data is Collected(データの取得)
Real World(現実世界)からデータを取得します。
Raw Data is Collected(データの取得)の前に、「ビジネスの理解」というステップがあります。ここでは、Raw Data is Collected(データの取得)に含まれていると解釈します。
- Data is Processed(データの加工)
データをモデリングや探索的データ分析が可能な形に加工します。
Clean Dataは、Data is Processed(データの加工)のアウトプットと解釈します。
- Exploratory Data Analysis(探索的データ分析)
より予測精度の高いモデルを作るためだけでなく、より説明性の高いモデルを作るためにも、データの理解は重要なステップです。
- Machine Learning Algorithms/Statistical Models(モデリング)
データを統計モデルや、機械学習モデル(アルゴリズム)にあてはめます。
Machine Learning Algorithms/Statistical Models(モデリング)の前に、「特徴量抽出」というステップがあります。ここでは、Machine Learning Algorithms/Statistical Models(モデリング)に含まれていると解釈します。
Machine Learning Algorithms/Statistical Models(モデリング)の後に、「評価」というステップがあります。ここでは、Machine Learning Algorithms/Statistical Models(モデリング)に含まれていると解釈します。
- Communicate/Visualizations/Report Findings(レポーティング)
レポーティングによる意思決定への貢献も、データサイエンスの重要な役割のひとつです。
- Built Data Product(展開)
モデルをビジネスの現場に展開(デプロイ)します。
Built Data Productは元々「製品への展開」を意味していたかもしれませんが、ここでは「ビジネス現場への展開」と広く捉えています。
Built Data Product(展開)の後に、「モニタリング」「再学習」というステップがあります。ここでは、Built Data Product(展開)に含まれていると解釈します。

